本篇目录:
- 1、山西农大软件工程考研率如何?
- 2、易基因|全基因组DNA甲基化测序分析全流程
- 3、利用分箱光滑技术可以进行什么
- 4、强力推荐!非常全的Python学习资料
- 5、数据仓库与数据挖掘实验_数据挖掘实验指导书
- 6、在数据挖掘过程中,好像有些算法要求变量必须是正太分布的,我想知道什...
山西农大软件工程考研率如何?
1、不高。这是由于当前考研总体环境比较激烈,每年考研报考人数很多,而软件工程专业作为其中的热门专业,报考的人数会更多,使得其考研难度变得更大,从而导致该专业考研通过率就比较低。
2、百分之五十四。根据查询山西农业大大学官网得知,2021年研究生报录比为百分之五十四,位居全省前十。山西农业大学,简称“山西农大”,是山西省人民政府与农业农村部共建的全国重点大学。
-图1")
3、山西农业大学考研率高的专业有草业专业、动物医学专业、农学专业。
易基因|全基因组DNA甲基化测序分析全流程
1、.甲基化特异性的PCR(Methylation-specific PCR,MSP)用亚硫酸氢盐处理基因组DNA,所有未发生甲基化的胞嘧啶被转化为尿嘧啶,而甲基化的胞嘧啶不变;随后设计针对甲基化和非甲基化序列的引物进行PCR。
2、) 重亚硫酸盐测序 该方法可以从单个碱基水平分析基因组中甲基化的胞嘧啶。首先,利用重烟硫酸盐对基因组DNA进行处理,将未发生甲基化的胞嘧啶脱氨基变成尿嘧啶。
3、常用的DNA甲基化检测方法包括:甲基化特异性PCR(MSP)、全基因组甲基化测序(WGBS)、甲基化敏感限制性内切酶联PCR(MSRE-PCR)、甲基化特异性聚合酶链反等。
-图2")
4、下图是 illumina 的建库流程,由于只保留原始 BS 处理后链互补链作为测序模板,因此 read1 序列跟 BS 后链序列相同。常用的 WGBS 比对软件是 Bismark, Bismark 将参考基因组序列预先进行 C-T 和 G-A 2种转换。
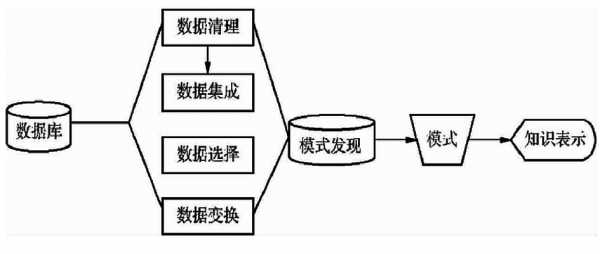
5、图 1 重亚硫酸盐转化&克隆测序[7]基于高通量测序的全基因组 DNA 甲基化检测方法 接下来,我们看一下第四个问题的另一种答案,我们用高通量测序来检测全基因组的 DNA 甲基化。
利用分箱光滑技术可以进行什么
1、数据光滑技术:分箱:通过考察数据的近邻(即周围的值)来光滑有序数据的值。有序值分布到一些“桶”或箱中,由于分箱方法考察近邻的值,因此进行局部光滑。一般来说,宽度越大光滑效果越大。
2、在进行噪声检查后,通常采用分箱、聚类、回归、计算机检查和人工检查结合等方法“光滑”数据,去掉数据中的噪声。分箱:分箱方法是一种简单常用的预处理方法,通过考察相邻数据来确定最终值。
-图3")
3、在采用分箱技术时,需要确定的两个主要问题就是:如何分箱以及如何对每个箱子中的数据进行平滑处理。分箱的方法:有4种:等深分箱法、等宽分箱法、最小熵法和用户自定义区间法。
强力推荐!非常全的Python学习资料
1、Python基础教程 《图灵程序设计丛书:Python基础教程(第2版 修订版)》包括Python程序设计的方方面面,首先从Python的安装开始,随后介绍了Python的基础知识和基本概念,包括列表、元组、字符串、字典以及各种语句。
2、python书籍推荐有:《Python编程:从入门到实践》《Head-First Python(2nd edition)》《“笨方法”学Python》《Python程序设计(第3版)》《像计算机科学家一样思考Python(第2版)》。
3、Python基础教程:是经典的Python入门教程书籍,本书层次鲜明,结构严谨。这本书既适合初学者夯实基础,又能帮助Python程序员提升技能,即使是Python方面的技术专家,也能从书里找到实用性极强的内容。
4、《笨方法学Python》、《流畅的python》、《EffectivePython:编写高质量Python代码的59个有效方法》、《PythonCookbook》。《利用Python进行数据分析(原书第2版)》、《Python数据科学手册(图灵出品)》。
数据仓库与数据挖掘实验_数据挖掘实验指导书
整个教学和实验中,我们强调学生切实培养动手实践能力,掌握数据挖掘的基本方法。
https://pan.baidu.com/s/1YozZOBkAvxPDn5EbRnriGQ 2006年清华大学出版社出版的图书 《数据仓库与数据挖掘教程》是2006年清华大学出版社出版的图书,作者是陈文伟。
数据仓库与数据挖掘都是从数据资源提取信息和知识进行辅助决策。由于数据资源丰富,数据仓库与数据挖掘辅助决策效果十分显著。本书对数据仓库的系统介绍,在于突出决策支持的本质。
韩家炜的数据挖掘概念与技术,还有本数据挖掘原理。优点是大家都说好,缺点是写的泛了点,看了还是很多不懂。
https://pan.baidu.com/s/1scFw3y9oOJSxC-8ImQ-iSw 《数据仓库与数据挖掘技术 》是2007年电子工业出版社出版的书籍,作者是陈京民。
在数据挖掘过程中,好像有些算法要求变量必须是正太分布的,我想知道什...
准备数据 建立模型之前的最后一步数据准备工作。可以把此步骤分为四个部分:选择变量,选择记录,创建新变量,转换变量。建立模型 建立模型是一个反复的过程。
有没有数据挖掘的案例可以来练习下,主要是来通过案例来知道算法是如何使用的...数据一共有17个特征,除了目标变量is_profit,还有16个特征。 以上的数据指标...主要需要关注的是 n_estimators ,即RF最大的决策树个数。
沃尔玛拥有世界上最大的数据仓库系统,为了能够准确了解顾客在其门店的购买习惯,沃尔玛对其顾客的购物行为进行购物篮分析,想知道顾客经常一起购买的商品有哪些。沃尔玛数据仓库里集中了其各门店的详细原始交易数据。
关联规则是描述数据库中数据项之间所存在的关系的规则,即根据一个事务中某些项的出现可导出另一些项在同一事务中也出现,即隐藏在数据间的关联或相互关系。
到此,以上就是小编对于数据挖掘实验心得的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏