本篇目录:
hadoop对海量数据进行什么处理
1、Hadoop是一个开源框架,用于分布式处理海量数据。它通过将数据分散存储在多个节点上,实现了高可用性和高扩展性。Hadoop采用了MapReduce模型,将数据划分为小块,由多个节点并行处理,最终将结果汇总得到最终结果。
2、数据分区和分片。在处理海量数据时,数据分区和分片是非常重要的技术。数据分区将数据划分为较小的块,每个块可以在不同的计算节点上并行处理。
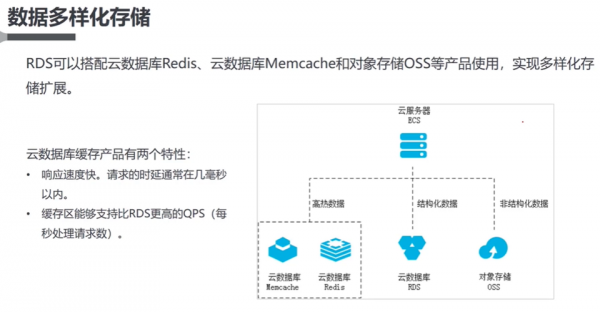
-图1")
3、使用大数据技术:大数据技术可以有效地处理海量数据,例如,使用Hadoop的MapReduce框架、使用NoSQL数据库等。使用实时分析工具:实时分析工具可以帮助用户实时分析海量数据,快速发现数据中的规律和趋势。
4、使用分布式计算框架:分布式计算框架可以将大量数据拆分成小块,然后分配给多个计算节点进行处理。这样可以在不增加硬件资源的情况下提高计算速度。
数据处理方式
数据处理最基本的四种方法列表法、作图法、逐差法、最小二乘法。数据处理,是对数据的采集、存储、检索、加工、变换和传输。根据处理设备的结构方式、工作方式,以及数据的时间空间分布方式的不同,数据处理有不同的方式。
数据处理主要有四种分类方式①根据处理设备的结构方式区分,有联机处理方式和脱机处理方式。②根据数据处理时间的分配方式区分,有批处理方式、分时处理方式和实时处理方式。
-图2")
可分为批处理和实时数据处理方式两种。批处理:也称为批处理脚本。顾名思义,批处理就是对某对象进行批量的处理,通常被认为是一种简化的脚本语言,它应用于DOS和Windows系统中。批处理文件的扩展名为bat。
图示法:是用图象来表示物理规律的一种实验数据处理方法。一般来讲,一个物理规律可以用三种方式来表述:文字表述、解析函数关系表述、图象表示。
数据处理的基本流程一般包括以下几个步骤:数据收集:从数据源中获取数据,可能是通过传感器、网络、文件导入等方式。数据清洗:对数据进行初步处理,包括去重、缺失值填充、异常值处理等。
linux搭建hadoop步骤linux搭建hadoop
1、安装hadoop 1 因为hadoop是基于java的,所以要保证hadoop能找到在本地系统中大路径,即正确设置java的环境变量。
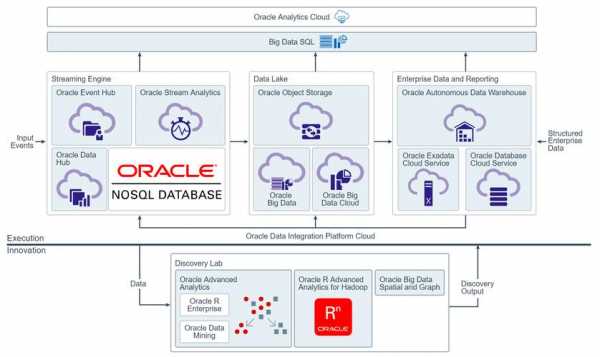
-图3")
2、JDK 6或更高版本; SSH(安全外壳协议),推荐安装OpenSSH。下面简述一下安装这两个程序的原因: Hadoop是用Java开发的,Hadoop的编译及MapReduce的运行都需要使用JDK。
3、②将master上的authorized_keys放到其他linux的~/.ssh目录下。命令:sudo scp authorized_keys hadoop@1192:~/.ssh sudo scp authorized_keys 远程主机用户名@远程主机名或ip:存放路径。
如何模拟hadoop测试数据处理
目前支持hadoopx(MRv1)、Hadoopx(MRv2)、Hadoopx(Yarn)三个版本的Hadoop集群的日志数据源收集,在日志管理运维方面还是处于一个国际领先的地位,目前国内有部分的数据驱动型公司也正在采用Splunk的日志管理运维服务。
选择开始菜单中→程序→【ManagementSQLServer2008】→【SQLServerManagementStudio】命令,打开【SQLServerManagementStudio】窗口,并使用Windows或SQLServer身份验证建立连接。
MapReduce将数据处理分为两个阶段:Map阶段和Reduce阶段。在Map阶段,数据被分解成小块,并执行指定的Map函数;在Reduce阶段,Map阶段的结果被汇总和执行指定的Reduce函数。
Hadoop模型 Hadoop的工作原理是将一个非常大的数据集切割成一个较小的单元,以能够被查询处理。同一个节点的计算资源用于并行查询处理。
HadoopHadoop是一个能够对大量数据进行分布式处理的软件框架。但是Hadoop是以一种可靠、高效、可伸缩的方式进行处理的。FusionTables可以添加到业务分析工具列表中。这也是最好的大数据分析工具之一。
优点 Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
如何使用Hadoop读写数据库
1、。Hive 的目标是做成数据仓库,所以它提供了SQL,提供了文件-表的映射关系,又由于Hive基于HDFS,所以不提供Update,因为HDFS本身就不支持。
2、定义一个类似JAVA Bean的实体类,来与数据库的每行记录进行对应,通常这个类要实现Writable和DBWritable接口,来重写里面的4个方法以对应获取每行记录里面的各个字段信息。
3、因为MapReduce适合处理数 据很大且适合划分的数据,所以在处理这类数据时就可以用MapReduce做一些过滤,得到基本的向量矩阵,然后通过MPI进一步处理后返回结果,只有整 合技术才能更好地解决问题。
4、Hadoop开源工具:Hive:将SQL语句转换成一个hadoop任务去执行,降低了使用Hadoop的门槛。HBase:存储结构化数据的分布式数据库,habase提供数据的随机读写和实时访问,实现对表数据的读写功能。
到此,以上就是小编对于hadoop模式的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏