本篇目录:
flink框架的特点
高吞吐量和低延迟:Flink 框架能够处理大规模数据流,并且具有高吞吐量和低延迟的特性。这意味着它可以处理大量的数据,并且可以在很短的时间内完成数据处理任务。
Flink 是一个流处理框架,支持流处理和批处理,特点是流处理有限,可容错,可扩展,高吞吐,低延迟。
-图1")
flink的流处理特性:支持高吞吐量、低延迟和高性能流处理。支持带事件时间的窗口操作。支持有状态计算的恰好一次语义支持高度灵活的窗口操作,支持基于时间、计数、会话和数据驱动的窗口操作。
虽然,spark和storm的计算框架非常成熟,但是Flink仍然占据了一席之地。主要在于flink在设计event time处理模型上比较优秀:watermark的计算实时性高,输出延迟低,而且接受迟到数据没有spark那么受限。
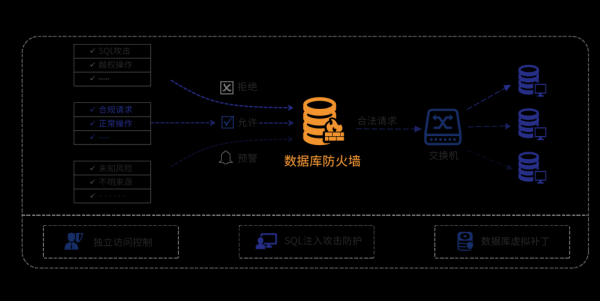
如何选择数据库存储引擎
InnoDB存储引擎 InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),其它存储引擎都是非事务安全表,支持行锁定和外键,MySQL5以后默认使用InnoDB存储引擎。
(3).idb:使用多表空间存储方式时,用于存放表数据和索引,若使用共享表空间存储则无此文件。 外键约束:InnoDB是MySQL唯一支持外键约束的引擎。
-图2")
你可以选择适用于服务器、数据库和表格的存储引擎,以便在选择如何存储你的信息、如何检索这些信息以及你需要你的数据结合什么性能和功能的时候为你提供最大的灵活性。
MyISAM存储引擎特别适合在以下几种情况下使用:选择密集型的表。MyISAM存储引擎在筛选大量数据时非常迅速,这是它最突出的优点。插入密集型的表。MyISAM的并发插入特性允许同时选择和插入数据。
常用的数据库引擎有哪些(数据库引擎区别)
Mysql数据库3种存储(MyISAM、MEMORY、InnoDB)引擎区别:Myisam是Mysql的默认存储引擎,当create创建新表时,未指定新表的存储引擎时,默认使用Myisam。MEMORY、InnoDB不是默认存储引擎。
InnoDB存储引擎 InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),其它存储引擎都是非事务安全表,支持行锁定和外键,MySQL5以后默认使用InnoDB存储引擎。
-图3")
InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比Myisam的存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
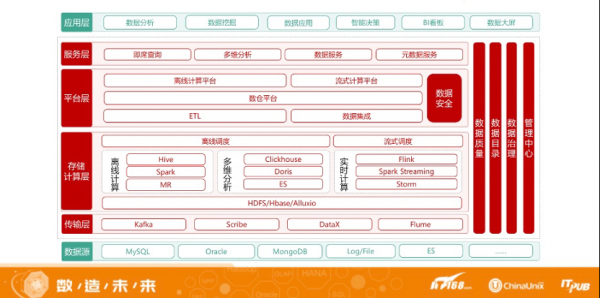
大数据常用组件
1、Hadoop三大核心组件分别是HDFS、MapReduce和YARN。HDFS是Hadoop生态系统中的分布式文件系统,用于存储大规模数据集。HDFS将数据分布在多个节点上,支持数据冗余备份,确保数据的可靠性和高可用性。
2、ZooKeeper ZooKeeper是Hadoop和Hbase的重要组件,是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组件服务等,在大数据开发中要掌握ZooKeeper的常用命令及功能的实现方法。
3、目前常用的大数据可视化软件与工具包括Tableau、Power BI、ECharts、Seaborn、QlikView。
4、hadoop三大组件是指Hadoop分布式文件系统、MapReduce和Yet Another Resource Negotiator。HDFS:Hadoop分布式文件系统是Hadoop的分布式文件系统,它是将大规模数据分散存储在多个节点上的基础。
5、数据挖掘算法的组件包括:神经网络,遗传算法,回归算法,聚类分析算法,贝耶斯算法。LR有很多方法来对模型正则化。比起NB的条件独立性假设,LR不需要考虑样本是否是相关的。
到此,以上就是小编对于数据处理引擎CQL的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏