


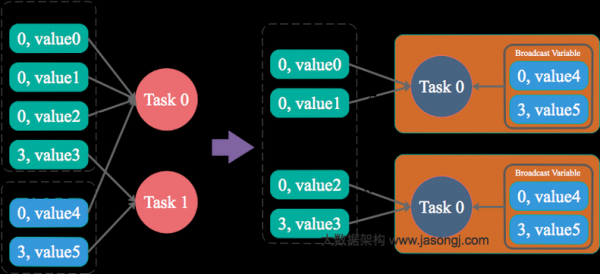
Sparkstreaming批量读取数据源中的数据,然后把每个batch转化成内部的RDD,Sparkstreaming以batch为单位进行计算,而不是以Tuple为单位,大大减少了ack所需的开销,显著提高了吞吐,大数据的四种主要计...
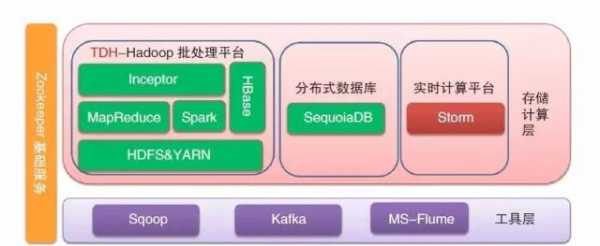
1、Hadoop主要是分布式计算和存储的框架,所以Hadoop工作过程主要依赖于HDFS分布式存储系统和Mapreduce分布式计算框架,2、Hadoop的框架最核心的设计就是:HDFS和MapReduce,HDFS为海量的数据提供了存储,...
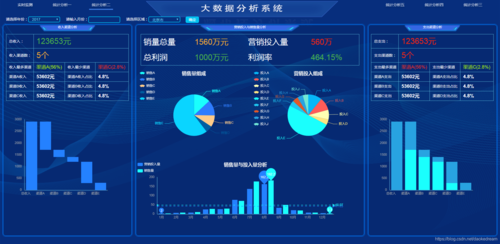
可视化分析可视化可以直观的展示数据,让数据自己说话,让观众听到结果,实时营销决策:通过大数据分析,企业可以实时监测市场和客户的变化,及时采取营销决策,包括价格调整、促销活动等,从而实现营销的灵活性和时效性,实现工作流程:这牵涉到流转过程的...
1、spark是一个通用计算框架,Spark是一个通用计算框架,用于快速处理大规模数据,Spark是一种与Hadoop相似的开源集群计算环境,但Spark在内存中执行任务,比Hadoop更快,2、Spark是一种通用的大数据计算框架,和传统...
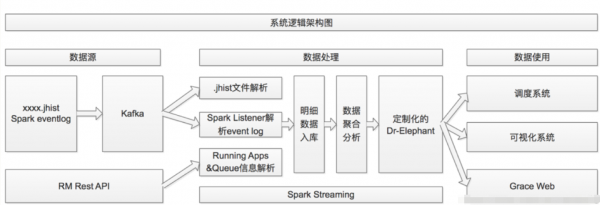
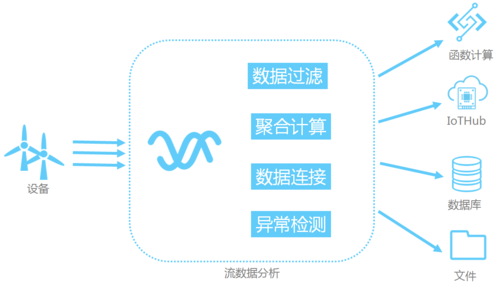
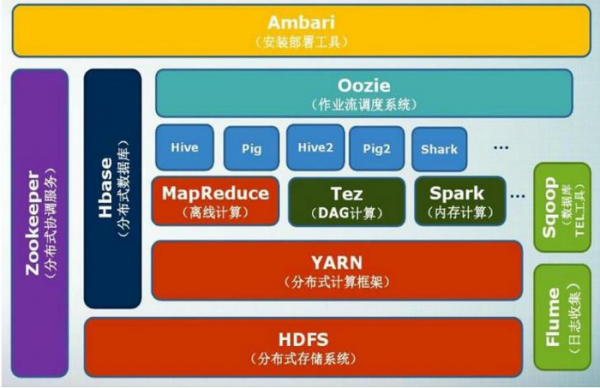
1、你好,目前大数据常用的工具有ApacheHadoop、ApacheSpark、ApacheStorm、ApacheCassandra、ApacheKafka等等,下面分别介绍一下这几种工具:Hadoop用于存储过程和分析大数据...
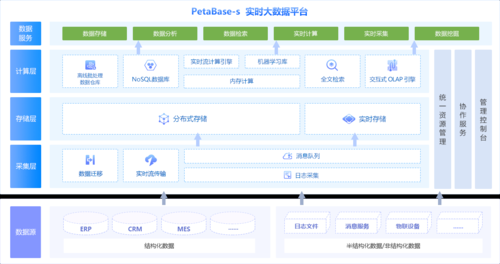
它和Pig差不多掌握一个就可以了,5、ApacheDolphinScheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度平台,致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。...
