本篇目录:
- 1、hadoop是做什么的
- 2、hadoop生态圈中的框架不包括什么
- 3、如何搭建基于Hadoop的大数据平台
- 4、怎么开发大数据平台
- 5、如何架构大数据系统hadoop
- 6、hive底层依赖hadoop中的哪些框架
hadoop是做什么的
节点数: 15台机器的构成的服务器集群服务器配置: 8核CPU,16G内存,4T硬盘容量。 HADOOP在百度:HADOOP主要应用日志分析,同时使用它做一些网页数据库的数据挖掘工作。节点数:10 - 500个节点。
Cloudera Hadoop是Cloudera发行的Hadoop版本,由于Hadoop深受客户欢迎,许多公司都推出了各自版本的Hadoop,也有一些公司则围绕Hadoop开发产品。在Hadoop生态系统中,规模最大、知名度最高的公司则是Cloudera。
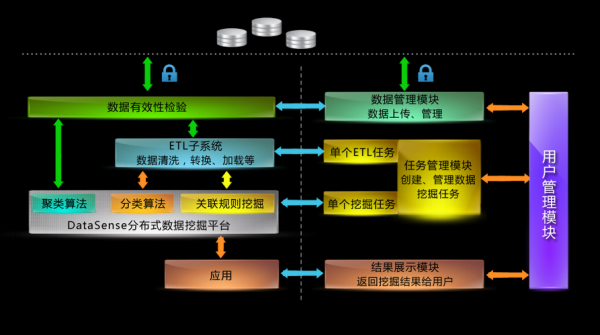
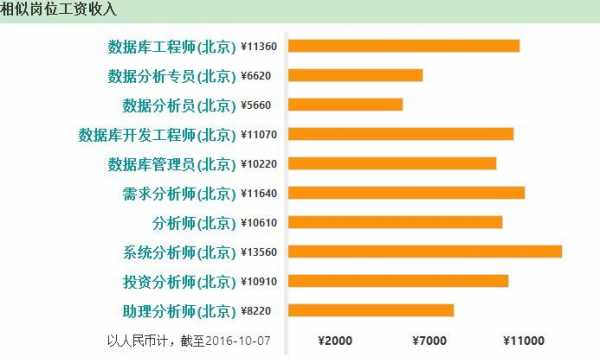
-图1")
SQL:大数据的特点是数据量大,所以大数据的核心之一就是数据存储。所以大数据工作对数据库的要求很高,甚至很多公司单独设置数据库开发工程师。
大数据工程师做什么?需要具备什么能力?大数据是眼下非常时髦的技术名词,与此同时自然也催生出了一些与大数据处理相关的职业,通过对数据的挖掘分析来影响企业的商业决策。
首先搞清楚什么是hadoop以及hadoop可以用来做什么?然后,可以从最经典的词频统计程序开始,初步了解MapReduce的基本思路和处理数据的方式。接着,就可以正式学习hadoop的基本原理,包括HDFS和MapReduce,先从整体,宏观核心原理看,先别看源码级别。
hadoop生态圈中的框架不包括什么
hadoop三大组件不包括所有分布式结构。广义上的Hadoop是指Hadoop的整个技术生态圈但不包括所有分布式。狭义上的Hadoop指的是其核心三大组件,包括HDFS、YARN及MapReduce.Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
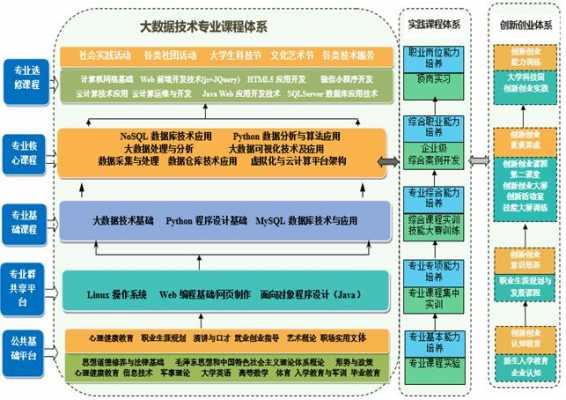
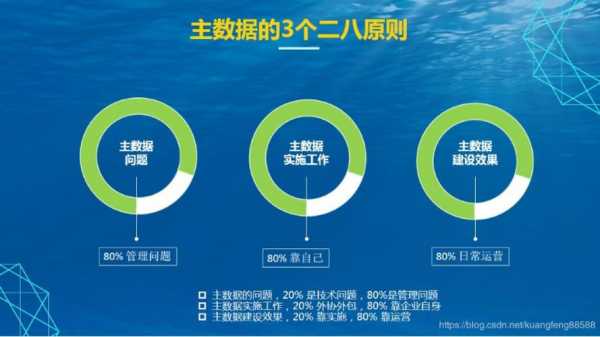
-图2")
其中一些项目是Hadoop本身,MapReduce,Hive,Pig,Zookeeper等。但这并不意味着所有的大数据处理技术都包含在Hadoop生态系统中。例如,Apache Spark是另一个流行的大数据处理框架,并不在Hadoop生态系统的核心组件中。
hadoop的特性不包括如下:目前开源hadoop只包含hdfs,mr,和yarn,yarn是hadoop2新增组件。hdfs是hadoop分布式文件系统,主要采用多备份方式存储文件,可以对接hive和hbase等产品并存储对应数据。
MAPREDUCE(分布式运算编程框架):解决海量数据计算 广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop也是apache开源大数据的一个生态圈总称,里面包含跟大数据开源框架的一些软件,包含hdfs,hive,zookeeper,hbase等等;Hadoop的框架最核心的设计就是:HDFS和MapReduce。
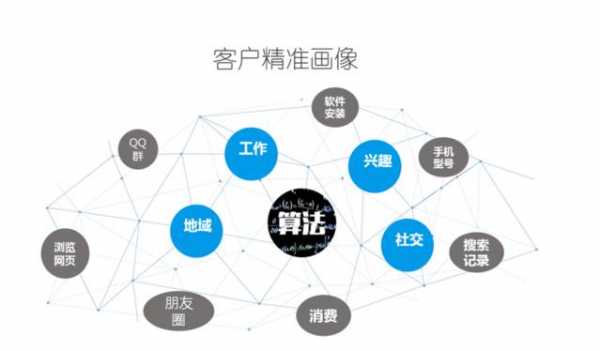
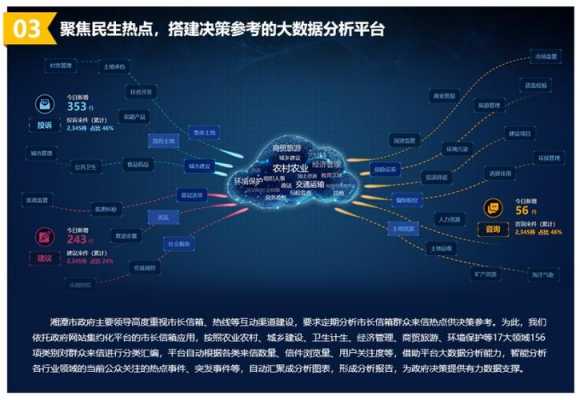
-图3")
如何搭建基于Hadoop的大数据平台
多年来在严苛的业务需求和数据压力下,我们几乎尝试了所有可能的大数据分析方法,最终落地于Hadoop平台之上。
操作体系的挑选 操作体系一般使用开源版的RedHat、Centos或许Debian作为底层的构建渠道,要根据大数据渠道所要建立的数据剖析东西能够支撑的体系,正确的挑选操作体系的版本。
云计算很早就解决了弹性建设的问题,我们可以按需进行大数据平台建设,并伴随业务的增长而快速弹性伸缩,企业可以做到按需支付成本。
一般的大数据平台从平台搭建到数据分析大概包括以下几个步骤:Linux系统安装。分布式计算平台或组件安装,当前分布式系统的大多使用的是Hadoop系列开源系统。数据导入。数据分析。一般包括两个阶段:数据预处理和数据建模分析。
大数据平台的搭建步骤:linux系统安装 一般使用开源版的Redhat系统--CentOS作为底层平台。为了提供稳定的硬件基础,在给硬盘做RAID和挂载数据存储节点的时,需要按情况配置。
怎么开发大数据平台
1、乐于学习 一般工程师通常只在需要某种技能的情况下才开始进行学习。优秀的工程师会对各种知识保持开放的学习状态。
2、大数据开发又分为平台开发和应用开发:大数据平台开发:针对于大数据系统平台本身进行开发,比如说国内的BAT为代表的头部企业,以及一些独角兽企业,都是有自身的大数据平台的。
3、大数据开发有两种,一种需要编写Spark、Hadoop的应用程序,另一种需要开发大数据处理系统本身。
如何架构大数据系统hadoop
在海量数据下,数据冗余模块往往成为整个系统的瓶颈,建议使用一些比较快的内存nosql来冗余原始数据,并采用尽可能多的节点进行并行冗余;或者也完全可以在Hadoop中执行批量Map,进行数据格式的转化。
Hadoop分布式文件系统(HDFS)将数据文件切割成数据块,并将其存储在多个节点之内,以提供容错性和高性能。除了大量的多个节点的聚合I/O,性能通常取决于数据块的大小——如128MB。
Hadoop通用:提供Hadoop模块所需要的Java类库和工具。Hadoop YARN:提供任务调度和集群资源管理功能。Hadoop HDFS:分布式文件系统,提供高吞吐量的应用程序数据访问方式。
hive底层依赖hadoop中的哪些框架
1、Hive是基于Hadoop平台的,它提供了类似SQL一样的查询语言HQL。
2、MapReduce框架可以自动管理任务的调度、容错、负载均衡等问题,使得Hadoop可以高效地运行大规模数据处理任务。YARN是Hadoop 0引入的新一代资源管理器,用于管理Hadoop集群中的计算资源。
3、Hadoop处理完全依赖于MapReduce框架,这要求用户了解Java编程的高级样式,以便成功查询数据。Apache Hive背后的动机是简化查询,并将Hadoop非结构化数据开放给公司中更广泛的用户群。Hive有三个主要功能:数据汇总,查询和分析。
到此,以上就是小编对于hadoop 数据仓库的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏