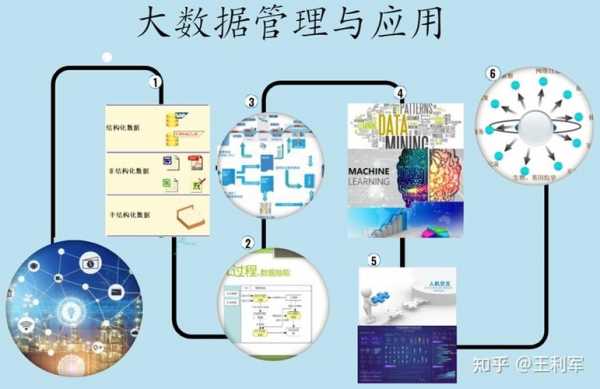
本篇目录:
对于社交网络的数据挖掘应该如何入手,使用哪些算法
遗传算法 遗传算法是一种基于生物自然选择与遗传机理的随机搜索算法,是一种仿生全局优化方法。遗传算法具有的隐含并行性、易于和其它模型结合等性质使得它在数据挖掘中被加以应用。
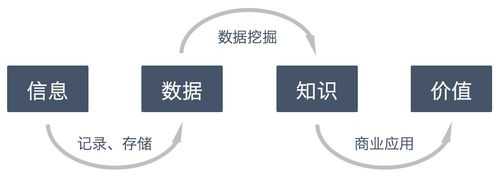
数据理解:尝试收集部分数据,然后对数据进行探索,包括数据描述、数据质量验证等。这有助于你对收集的数据有个初步的认知。数据准备:开始收集数据,并对数据进行清洗、数据集成等操作,完成数据挖掘前的准备工作。
-图1")
)清洗:对于大数据,并不全是有价值的,有些数据并不是我们所关心的内容,而另一些数据则是完全错误的干扰项,因此要对数据通过过滤“去噪”从而提取出有效数据。
分布式计算,非结构化数据库,分类、聚类等算法。大数据包括结构化、半结构化和非结构化数据,非结构化数据越来越成为数据的主要部分。据IDC的调查报告显示:企业中80%的数据都是非结构化数据,这些数据每年都按指数增长60%。
社交网络数据:一些社交媒体APP可以访问我们的社交网络数据,包括好友列表、发布内容、点赞和评论等。这些数据可以用于提供个性化的内容和广告,也可以用于识别我们的兴趣和偏好。
数据挖掘十大算法-
最大期望算法(Expectation–Maximization Algorithm, EM)[7]是从概率模型中寻找参数最大似然估计的一种算法。其中概率模型依赖于无法观测的隐性变量。最大期望算法经常用在机器学习和计算机视觉的数据聚类(Data Clustering)领域。
-图2")
AdaBoostAdaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器 (强分类器)。
大数据挖掘的算法:朴素贝叶斯,超级简单,就像做一些数数的工作。如果条件独立假设成立的话,NB将比鉴别模型收敛的更快,所以你只需要少量的训练数据。即使条件独立假设不成立,NB在实际中仍然表现出惊人的好。
求数据挖掘考试题
再说置信度:置信度是说在存在一个元素的集合中另外一个元素存在的概率。我们还用第二题举例:比如在存在A的集合中存在B的概率是多少?我们找找:存在A的集合有1,2,3三个。在这三个中1,2,两个包含B。
【答案】:B、C、D、E 数据源必须是真实的、大量的、有噪声的; 发现的是用户感兴趣的知识; 发现的知识是可接受、可理解、可运用的; 并不要求发现放之四海而皆准的知识,仅支持特定的发现问题。
-图3")
最小-最大规范化对原始数据进行线性变换。假定minA 和maxA 分别为属性A的最小和最大值,通过公式可以将 A 的值 v映射到区间[new_minA ,new_maxA ]中的 v’。
可以食用的果核有哪些?它的营养价值?
我要告诉你,牛油果的核是可以被食用的。虽然不像果肉那样柔软可口,但它确实具有一些营养价值。牛油果核富含纤维、抗氧化剂和健康脂肪酸。纤维对于促进消化系统健康非常重要,并可帮助减轻便秘问题。
想具体了解可以和我一起去看看,同时我也会告诉大家吃菠萝蜜时会有哪些禁忌。
菠萝蜜核大枣粥补血降压 菠萝蜜核中含有高量的钾,对于缓解血压过高有很好帮助,大枣一直都是滋阴补血的保健品,两者一起食用即营养又美味。菠萝蜜核纹鸡益气补肾。
牛油果是一种营养价值很高的水果,果肉柔软似乳酪,色黄,风味独特,含多种维生素、丰富的脂肪和蛋白质,钠、钾、镁、钙等含量也高。因牛油果似乳酪一般软滑、细腻的口感,很多人误以为它是一种胆固醇很高的不健康水果。
到此,以上就是小编对于数据挖掘计算题及答案的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏