本篇目录:
怎么爬取element中的数据
1、使用xpath helper或者是chrome中的copy xpath都是从element中提取的数据。JSONView插件,方便查看json数据,有时候url里有callback参数,可以直接去除,得到想要的数据。
2、使用selenium库中的find_element_by_xpath()方法来获取目标element,可以关闭Chrome浏览器,并对获取到的body内容进行处理或存储。
-图1")
3、对于这种动态加载的网站,建议使用第三方库selenium爬取。它可以完全模拟浏览器,等待网站全部加载完成后再进行数据的自动获取。
4、让我找到了。下面是区分字段后的效果: 需要点击抓取更多数据这个按钮添加新的要抓取的字段!分页抓取 如需要抓取其它页的数据就这样做。
5、您可以按照以下步骤来配置八爪鱼采集器进行数据采集: 打开八爪鱼采集器,并创建一个新的采集任务。 在任务设置中,输入要采集的网址作为采集的起始网址。 配置采集规则。
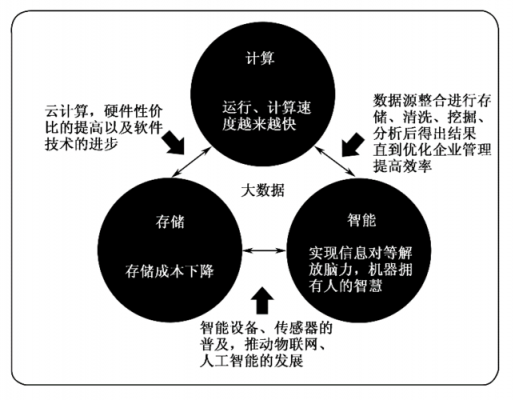
6、,首先获取到后端返回给我们的权限数据,数据大概长这么个样子。2,要渲染到element的树形结构上的话,要做一层递归处理,让它形成树形结构。这个也可以不用递归,我看他们用map这个属性,也能很好的处理。
-图2")
python怎么爬取数据
1、用python爬取网站数据方法步骤如下:首先要明确想要爬取的目标。对于网页源信息的爬取首先要获取url,然后定位的目标内容。先使用基础for循环生成的url信息。
2、以下是使用Python编写爬虫获取网页数据的一般步骤: 安装Python和所需的第三方库。可以使用pip命令来安装第三方库,如pip install beautifulsoup4。 导入所需的库。例如,使用import语句导入BeautifulSoup库。
3、以下是使用Python3进行新闻网站爬取的一般步骤: 导入所需的库,如requests、BeautifulSoup等。 使用requests库发送HTTP请求,获取新闻网站的HTML源代码。 使用BeautifulSoup库解析HTML源代码,提取所需的新闻数据。
如何用python爬取网站数据
1、selenium是一个自动化测试工具,也可以用来模拟浏览器行为进行网页数据抓取。使用selenium库可以执行JavaScript代码、模拟点击按钮、填写表单等操作。
-图3")
2、用python爬取网站数据方法步骤如下:首先要明确想要爬取的目标。对于网页源信息的爬取首先要获取url,然后定位的目标内容。先使用基础for循环生成的url信息。
3、爬取网页数据,需要一些工具,比如requests,正则表达式,bs4等,解析网页首推bs4啊,可以通过标签和节点抓取数据。
4、)首先确定需要爬取的网页URL地址;2)通过HTTP/HTTP协议来获取对应的HTML页面;3)提取HTML页面里有用的数据:a.如果是需要的数据,就保存起来。b.如果是页面里的其他URL,那就继续执行第二步。
5、《Python爬虫数据分析》:这本书介绍了如何分析爬取到的数据,以及如何使用Python编写爬虫程序,实现网络爬虫的功能。
6、递归警告:Python默认的递归限制是1000次,因为维基百科的链接浩如烟海,所以这个程序达到递归限制后就会停止。如果你不想让它停止,你可以设置一个递归计数器或者其他方法。
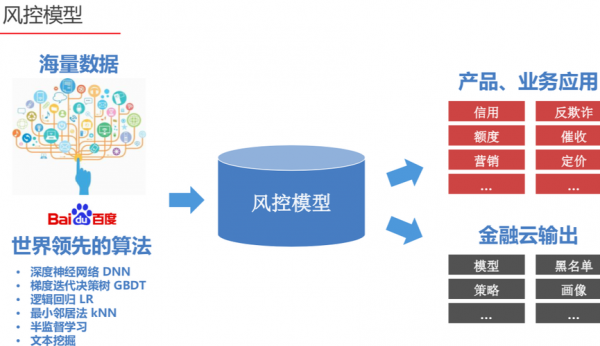
在数据挖掘中利用爬虫原理爬取数据需要引用哪个库?
Python爬虫网络库Python爬虫网络库主要包括:urllib、requests、grab、pycurl、urllibhttplibRoboBrowser、MechanicalSoup、mechanize、socket、Unirest for Python、hyper、PySocks、treq以及aiohttp等。
第一数据获取:request,BeautifulSoup 第二基本数学库:numpy 第三 数据库出路 pymongo 第四 图形可视化? matplotlib 第五 树分析基本的库 pandas 数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。
日志采集。通过爬虫的方式常爬取的数据源主要来自这四类数据源包括,开放数据源、爬虫抓取、传感器和日志采集,开放数据源是针对行业的数据库。
matplotlib matplotlib是最流行的用于绘制图表和其他二维数据可视化的Python库。它最初由John D.Hunter(JDH)创建,目前由一个庞大的开发团队维护。它非常适合创建出版物上用的图表。
到此,以上就是小编对于数据爬取分析案例的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏