本篇目录:
pdsn是什么意思
相对于CDMAOne网络,与CDMA 2000系统相关联的PDSN是一个新部件。在处理所提供的分组数据业务时,PDSN是一个基本单元。
所谓异构是指两个或以上的无线通信系统采用了不同的接入技术,或者是采用相同的无线接入技术但属于不同的无线运营商。
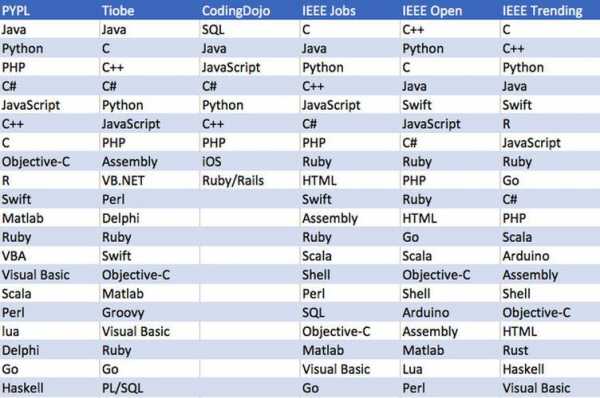
-图1")
PDSN升级为HSGW(HRPDServingGateway),即HRPD服务网关。当然从这里可以看出,对于BTS,eHRPD与HRPD没有差异,也就是说eHRPD改善了网络融合方式,使资源能合理利用但是没有改善无线侧的能力,这点非常关键。
怎样学习大数据
1、学习大数据的方法:关注一些大数据领域的动态,让自己融入大数据这样一个大的环境中。然后找一些编程语言的资料(大数据的基础必备技能)和大数据入门的视频和书籍,基本的技术知识还是要了解的。
2、了解大数据的理论知识 要学习大数据课程,首先需要对课程有一个简单的了解,了解课程的内容,并学习主要知识。最重要的是需要知道什么是大数据。开始应该简单地了解大数据,看看您是否真的对大数据学习感兴趣。
3、首先要学习编程语言,学完了编程语言之后,一般就可以进行大数据部分的课程学习了,大数据的专业课程有Linux,Hadoop,Scala, HBase, Hive, Spark等。如果要完整的学习大数据的话,这些课程都是必不可少的。
-图2")
4、新手学习大数据可以通过自学或是培训两种方式。想要自学那么个人的学历不能低于本科,若是计算机行业的话比较好。
5、(3)数据库:hive、hadoop、impala等数据库相关的知识可以学习;(3)辅助工具:比如思维导图软件(如MindManager、MindNode Pro等)也可以很好地帮助我们整理分析思路。
6、高度技术化:大数据基础涉及到丰富的数据管理和数据处理技术,例如分布式系统、Hadoop等,同时也需要掌握数据清洗、数据统计等理论知识。因此,学习大数据基础需要具备较高的技术水平,需要具备一定的计算机科学和数学基础。
大数据中的Spark指的是什么?
Spark是云计算大数据的集大成者,是Hadoop的取代者,是第二代云计算大数据技术。
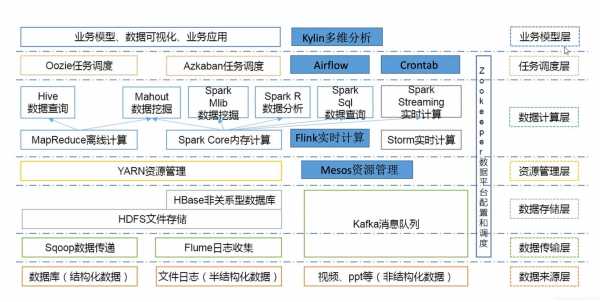
-图3")
spark是一个通用计算框架。Spark是一个通用计算框架,用于快速处理大规模数据。Spark是一种与Hadoop相似的开源集群计算环境,但Spark在内存中执行任务,比Hadoop更快。
Spark是基于内存,是云计算领域的继Hadoop之后的下一代的最热门的通用的并行计算框架开源项目,尤其出色的支持Interactive Query、流计算、图计算等。Spark在机器学习方面有着无与伦比的优势,特别适合需要多次迭代计算的算法。
Spark,是一种One Stackto rule them all的大数据计算框架,期望使用一个技术堆栈就完美地解决大数据领域的各种计算任务。Apache官方,对Spark的定义就是:通用的大数据快速处理引擎。
什么是并行计算?如何实现并行计算
并行计算是一种同时使用多个处理器或计算机来解决问题的计算模式。与串行计算(即单个处理器或计算机一次处理一个任务)相比,它可以显著加速计算,提高效率,并在科学、工程等领域中得到广泛应用。
并行计算的概念是一种同时执行多个计算任务的方法,通过将问题划分为多个小任务,并同时处理这些任务来提高计算效率。在并行计算中,任务的执行可以是同时进行的,也可以是按照某种调度顺序进行的。
并行计算是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。
并行计算(Parallel Computing)是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。
并行计算(ParallelComputing)是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。分布式计算会是一个比较松散的结构,并行计算则是各节点之间通过高速网络或其它总线之类的东西连接。
Storm与Spark,Hadoop相比是否有优势
1、Storm用于处理高速、大型数据流的分布式实时计算系统。为Hadoop添加了可靠的实时数据处理功能 Spark采用了内存计算。从多迭代批处理出发,允许将数据载入内存作反复查询,此外还融合数据仓库,流处理和图形计算等多种计算范式。
2、spark与hadoop的比较我就不多说了,除了对硬件的要求稍高,spark应该是完胜hadoop(Map/Reduce)的。storm与spark都可以用于流计算,但storm对应的场景是毫秒级的统计与计算,而spark(stream)对应的是秒级的。
3、应用场景不同不好比较。一般storm拿来做实时流数据的需求,而spark更适合拿来做离线数据分析。
4、Storm在动态处理大量生成的“小数据块”上要更好(比如在Twitter数据流上实时计算一些汇聚功能或分析)。
5、spark和hadoop的区别:诞生的先后顺序、计算不同、平台不同。诞生的先后顺序,hadoop属于第一代开源大数据处理平台,而spark属于第二代。属于下一代的spark肯定在综合评价上要优于第一代的hadoop。
6、storm 是流式处理的老大。 速度快 即时通讯。 淘宝的JStorm 可以达到百万级每秒。spark 是对 hadoop 的 MR 的改进。 由于 MR 需要不断的将数据落盘,互相拉取导致 IO 大。
到此,以上就是小编对于大数据并行计算框架包括的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏