本篇目录:
带你了解数据挖掘中的经典算法
1、KNN算法 KNN算法的全名称叫做k-nearest neighbor classification,也就是K最近邻,简称为KNN算法,这种分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
2、最大期望算法 在统计计算中,最大期望算法是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量。最大期望经常用在机器学习和计算机视觉的数据集聚领域。
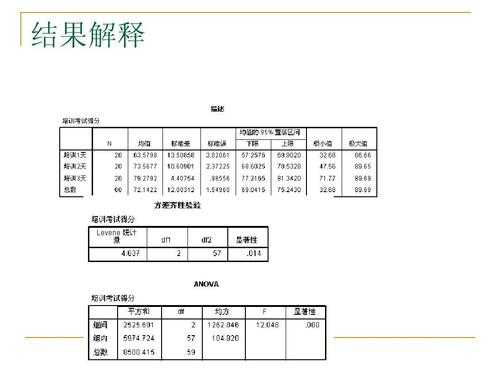
-图1")
3、不仅仅是选中的十大算法,其实参加评选的18种算法,实际上随便拿出一种来都可以称得上是经典算法,它们在数据挖掘领域都产生了极为深远的影响。
数据挖掘十大经典算法及各自优势
大数据挖掘的算法:朴素贝叶斯,超级简单,就像做一些数数的工作。如果条件独立假设成立的话,NB将比鉴别模型收敛的更快,所以你只需要少量的训练数据。即使条件独立假设不成立,NB在实际中仍然表现出惊人的好。
以下主要是常见的10种数据挖掘的算法,数据挖掘分为:分类(Logistic回归模型、神经网络、支持向量机等)、关联分析、聚类分析、孤立点分析。
最大期望算法 在统计计算中,最大期望算法是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量。最大期望经常用在机器学习和计算机视觉的数据集聚领域。
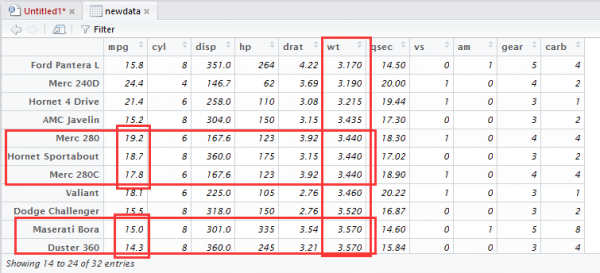
-图2")
打几个不恰当的比方 :另外,还有一个经常有人问起的问题,就是 数据挖掘 和 机器学习 这两个概念的区别,这里一句话阐明我自己的认识:机器学习是基础,数据挖掘是应用。
在CART算法中主要分为两个步骤:将样本递归划分进行建树过程;用验证数据进行剪枝。 K-means k-平均算法(k-means clustering)[5]是源于信号处理中的一种向量量化方法,现在则更多地作为一种聚类分析方法流行于数据挖掘领域。
与决策树与SVM相比,还会得到一个不错的概率解释,甚至可以轻松地利用新数据来更新模型(使用在线梯度下降算法online gradient descent)。
四大经典算法最优
1、贝尔曼福特算法Bellman-Ford Algorithm:贝尔曼-福特算法用于求解单源最短路径问题,包括处理带有负权边的图。它通过对所有边进行松弛操作,反复迭代修改节点的距离值,直到找到最短路径或检测到负权环。
-图3")
2、算法六: BFS(广度优先搜索)广度优先搜索算法(Breadth-First-Search),是一种图形搜索算法。简单的说BFS是从根节点开始,活着树(图)的宽度遍历树(图)的节点。如果所有节点均被访问,则算法中止。BFS同样属于盲目搜索。
3、梯度下降法是一个最优化算法,通常也称为最速下降法。最速下降法是求解无约束优化问题最简单和最古老的方法之一,虽然现在已经不具有实用性,但是许多有效算法都是以它为基础进行改进和修正而得到的。
4、C语言大牛雅荐的七大经典排序算法冒泡排序 比较相邻的元素。
数据挖掘中的经典算法
KNN算法 KNN算法的全名称叫做k-nearest neighbor classification,也就是K最近邻,简称为KNN算法,这种分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
K-Means算法 K-means algorithm算法是一个聚类算法,把n的对象根据他们的属性分为k个分割,k大于n。它与处理混合正态分布的最大期望算法很相似,因为他们都试图找到数据中自然聚类的中心。
最大期望算法 在统计计算中,最大期望算法是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量。最大期望经常用在机器学习和计算机视觉的数据集聚领域。
K-means算法:是一种聚类算法。SVM:一种监督式学习的方法,广泛运用于统计分类以及回归分析中Apriori :是一种最有影响的挖掘布尔关联规则频繁项集的算法。EM:最大期望值法。
k-means algorithm算法是一个聚类算法,把n的对象根据他们的属性分为k个分割,k n。它与处理混合正态分布的最大期望算法很相似,因为他们都试图找到数据中自然聚类的中心。
到此,以上就是小编对于数据算法书籍的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏