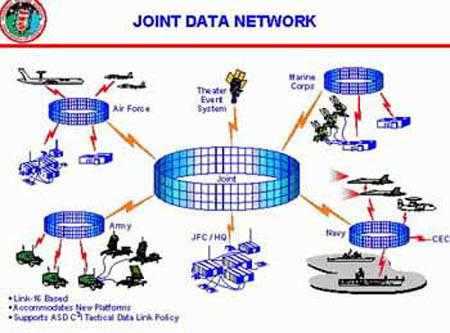
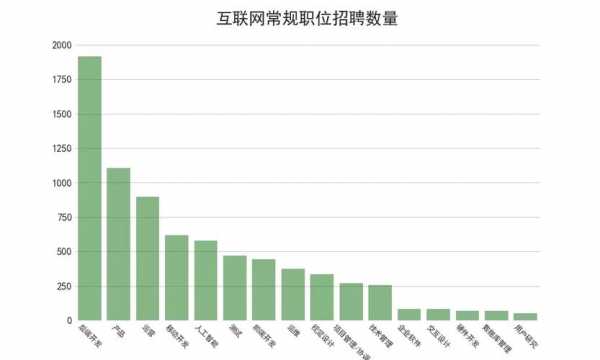
本篇目录:
数据挖掘十大算法-
1、最大期望算法(Expectation–Maximization Algorithm, EM)[7]是从概率模型中寻找参数最大似然估计的一种算法。其中概率模型依赖于无法观测的隐性变量。最大期望算法经常用在机器学习和计算机视觉的数据聚类(Data Clustering)领域。
2、AdaBoostAdaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器 (强分类器)。
-图1")
3、EM算法是一种迭代优化策略,由于它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步),一轮轮迭代更新隐含数据和模型分布参数,直到收敛,即得到我们需要的模型参数。
4、SVM:一种监督式学习的方法,广泛运用于统计分类以及回归分析中Apriori :是一种最有影响的挖掘布尔关联规则频繁项集的算法。EM:最大期望值法。pagerank:是google算法的重要内容。
数据挖掘常用算法有哪些?
K-means算法:是一种聚类算法。SVM:一种监督式学习的方法,广泛运用于统计分类以及回归分析中Apriori :是一种最有影响的挖掘布尔关联规则频繁项集的算法。EM:最大期望值法。
决策树算法办法 决策树算法是一种常见于预测模型的优化算法,它依据将很多数据信息有目地归类,从这当中寻找一些有使用价值的,潜在性的信息。它的要害优势是叙说简易,归类速度更快,十分适宜规模性的数据处理办法。
-图2")
聚类算法:将数据按照相似性进行分组,例如基于K-Means聚类、层次聚类等算法。关联规则挖掘:在数据集中发现项与项之间的相关性,例如Apriori算法等。
这种算法在数据挖掘中是十分常见的算法。支持向量机 而Support vector machines就是支持向量机,简称SV机(论文中一般简称SVM)。它是一种监督式学习的方法,这种方法广泛的应用于统计分类以及回归分析中。
利用数据挖掘进行数据分析常用的方法主要有分类、回归分析、聚类、关联规则、特征、变化和偏差分析、Web页挖掘等, 它们分别从不同的角度对数据进行挖掘。
大数据挖掘的算法有哪些?
有时也把数据挖掘分为:分类,回归,聚类,关联分析。
-图3")
遗传算法 遗传算法是一种基于生物自然选择与遗传机理的随机搜索算法,是一种仿生全局优化方法。遗传算法具有的隐含并行性、易于和其它模型结合等性质使得它在数据挖掘中被加以应用。
其中,数据挖掘经典十大算法为:C5,K-Means,SVM,Apriori,EM,PageRank,AdaBoost,KNN,NB和CART。常见的分布式计算有Hadoop Spark等,如果要实时计算的,一般用Storm什么的。
常用的数据挖掘算法分为以下几类:神经网络,遗传算法,回归算法,聚类分析算法,贝耶斯算法。
方法(数据挖掘算法)如果说可视化用于人们观看,那么数据挖掘就是给机器看的。集群、分割、孤立点分析和其他算法使我们能够深入挖掘数据并挖掘价值。这些算法不仅要处理大量数据,还必须尽量缩减处理大数据的速度。
Apriori算法,它是一种最具影响力的挖掘布尔关联规则频繁项集的算法。它的算法核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。
到此,以上就是小编对于数据挖掘计算题怎么做的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏