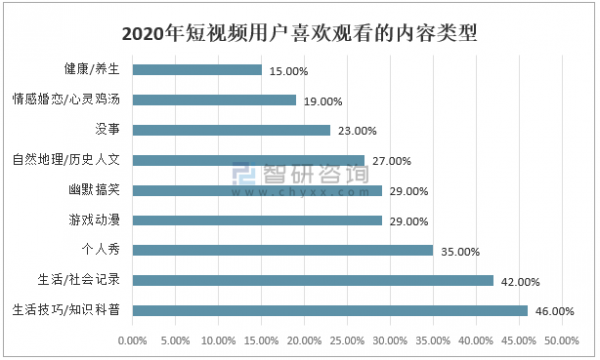
本篇目录:
百度是如何使用hadoop的
在百度,hadoop主要应用于以下几个方面:日志的存储和统计;网页数据的分析和挖掘;商业分析,如用户的行为和广告关注度等;在线数据的反馈,及时得到在线广告的点击情况;用户网页的聚类,分析用户的推荐度及用户之间的关联度。
Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。Hadoop实现了一个分布式文件系统(HadoopDistributedFileSystem),简称hdfs。
-图1")
hadoop集群部署方式以及使用场景如下:独立模式:又称为单机模式,在该模式下,无需运行任何守护进程,所有的程序都在单个JVM上执行。
Hadoop的Mapper是怎么从HDFS上读取TextInputFormat数据的
1、文件要存储在HDFS中,每个文件被切分成多个一定大小的块也就是Block,(Hadoop0默认为64M,Hadoop0默认为128M),并且默认3个备份存储在多个的节点中。
2、如果在读某个block是DFSInputStream检测到错误,DFSInputSteam就会连接下一个datanode以获取此block的其他备份,同时他会记录下以前检测到的坏掉的datanode以免以后再无用的重复读取该datanode。
3、我们使用了 就是InputFormat中的另一个方法createRecordReader() 这个方法:RecordReader:RecordReader是用来从一个输入分片中读取一个一个的K -V 对的抽象类,我们可以将其看作是在InputSplit上的迭代器。
-图2")
4、hadoop 在编码时都是写死的utf-8,如果文件编码为GBK,就会出现乱码。在mapper或reducer读取文本的时候,将Text转换下编码即可。编码转换使用下面的 transformTextToUtf8(Text text, String encoding) 。
如何使用Hadoop读写数据库
。Hive 的目标是做成数据仓库,所以它提供了SQL,提供了文件-表的映射关系,又由于Hive基于HDFS,所以不提供Update,因为HDFS本身就不支持。
选择开始菜单中→程序→【Management SQL Server 2008】→【SQL Server Management Studio】命令,打开【SQL Server Management Studio】窗口,并使用Windows或 SQL Server身份验证建立连接。
定义一个类似JAVA Bean的实体类,来与数据库的每行记录进行对应,通常这个类要实现Writable和DBWritable接口,来重写里面的4个方法以对应获取每行记录里面的各个字段信息。
-图3")
(3)Hive是Hadoop架构中的数据仓库,主要用于静态的结构以及需要经常分析的工作。 Hbase主要作为面向列的数据库运行在HDFS上,可存储PB级的数据。 Hbase利用MapReduce来处理内部的海量数据,并能在海量数据中定位所需的数据且访问它。
到此,以上就是小编对于hadoop20中hdfs的读入文件的工作原理的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏