本篇目录:
数据清理是什么意思
1、数据清洗是指把一些杂乱无章的,和不可用的数据清理掉,留下正常的可用数据,从而提高数据质量。
2、清除数据是删除软件使用产生的数据。“清除数据”功能可能导致相应软件中的聊天记录,下载的视频、图片永久丢失,因此在使用“清除数据”功能时,建议先保存备份软件中的重要数据。可以清除的媒介设备有磁盘、闪存设备、CD和DVD。
-图1")
3、顾名思义,数据清洗是清洗脏数据,是指在数据文件中发现和纠正可识别错误的最后一个程序,包括检查数据一致性、处理无效值和缺失值。
4、数据清理也称为数据清理,用于检测和纠正(或删除)记录集,表或数据库中的不准确或损坏的记录。广义上讲,数据清除或清除是指识别不正确,不完整,不相关,不准确或其他有问题的数据部分,然后替换,修改或删除该脏数据。
数据清洗的方法包括哪些
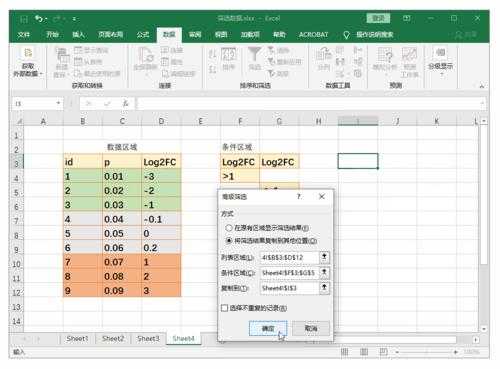
数据清洗的方法包括:解决不完整数据(即值缺失)的方法、错误值的检测及解决方法、重复记录的检测及消除方法、不一致性(数据源内部及数据源之间)的检测及解决方法。
通常来说,清洗数据有三个方法,分别是分箱法、聚类法、回归法。这三种方法各有各的优势,能够对噪音全方位的清理。
-图2")
通过身份证件号码推算性别、籍贯、出生日期、年龄(包括但不局限)等信息补全;通过前后数据补全;实在补不全的,对数据进行剔除。
清洗数据有三个方法,分别是分箱法、聚类法、回归法。这三种方法各有各的优势,能够对噪音全方位的清理。
etl清洗数据与spark数据清洗区别
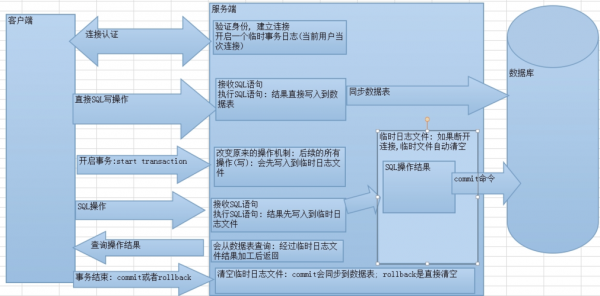
spark基于内存计算的准Mapreduce,在离线数据处理中,一般使用Spark sql进行数据清洗,目标文件一般是放在hdf或者nfs上,在书写sql的时候,尽量少用distinct,group by reducebykey 等之类的算子,要防止数据倾斜。
数据清洗:MapReduce作为Hadoop的查询引擎,用于大规模数据集的并行计算。数据查询分析:Hive的核心工作就是把SQL语句翻译成MR程序,可以将结构化的数据映射为一张数据库表,并提供HQL(HiveSQL)查询功能。
-图3")
数据收集:从数据源中获取数据,可能是通过传感器、网络、文件导入等方式。数据清洗:对数据进行初步处理,包括去重、缺失值填充、异常值处理等。
数据清洗的基本流程
数据清洗的基本流程一共分为5个步骤,分别是数据分析、定义数据清洗的策略和规则、搜寻并确定错误实例、纠正发现的错误以及干净数据回流。
数据清洗:对原始数据进行清洗和处理,包括删除重复数据、处理缺失值、纠正错误等。 数据转换:将原始数据从一种格式转换为另一种格式,以便后续分析。
数据预处理阶段。缺失值清洗。格式内容清洗。逻辑错误清洗。非需求数据清洗(也就是不需要的字段)。
到此,以上就是小编对于数据清洗的方法包括哪些的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏