本篇目录:
- 1、十三种常用的数据挖掘的技术
- 2、文本数据挖掘的介绍
- 3、什么是数据挖掘
十三种常用的数据挖掘的技术
下面着重讨论一下数据挖掘中常用的一些技术:统计技术,关联规则,基于历史的分析,遗传算法,聚集检测,连接分析,决策树,神经网络,粗糙集,模糊集,回归分析,差别分析,概念描述等十三种常用的数据挖掘的技术。
统计学 统计学是最基本的数据挖掘技术,特别是多元统计分析。 聚类分析和模式识别 聚类分析主要是根据事物的特征对其进行聚类或分类,即所谓物以类聚,以期从中发现规律和典型模式。
-图1")
决策树技术。决策树是一种非常成熟的、普遍采用的数据挖掘技术。在决策树里,所分析的数据样本先是集成为一个树根,然后经过层层分枝,最终形成若干个结点,每个结点代表一个结论。神经网络技术。
神经网络法 神经网络法是模拟生物神经系统的结构和功能,是一种通过训练来学习的非线性预测模型,它将每一个连接看作一个处理单元,试图模拟人脑神经元的功能,可完成分类、聚类、特征挖掘等多种数据挖掘任务。
神经网络作为一种先进的人工智能技术,因其自身自行处理、分布存储和高度容错等特性非常适合处理非线性的问题,以及那些以模糊、不完整、不严密的知识或数据为特征的问题,它的这一特点十分适合解决数据挖掘的问题。
文本数据挖掘的介绍
文本挖掘指的是从文本数据中获取有价值的信息和知识,它是数据挖掘中的一种方法。文本挖掘中最重要最基本的应用是实现文本的分类和聚类,前者是有监督的挖掘算法,后者是无监督的挖掘算法。
-图2")
文本数据挖掘 是一种利用计算机处理技术从文本数据中抽取有价值的信息和知识的应用驱动型学科。
文本挖掘(TextMinin)是一个从非结构化文本信息中获取用户感兴趣或者有用的模式的过程。文本挖掘的主要目的是从非结构化文本文档中提取有趣的、重要的模式和知识。可以看成是基于数据库的数据挖掘或知识发现的扩展。
什么是数据挖掘
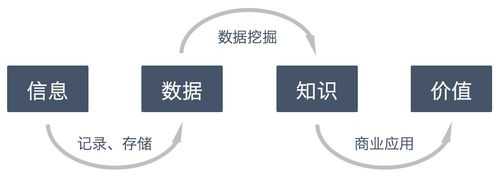
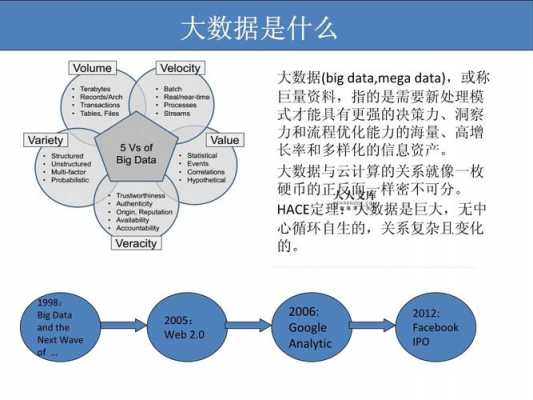
数据挖掘又译为资料探勘、数据采矿。是一种透过数理模式来分析企业内储存的大量资料,以找出不同的客户或市场划分,分析出消费者喜好和行为的方法,它是数据库知识发现中的一个步骤。
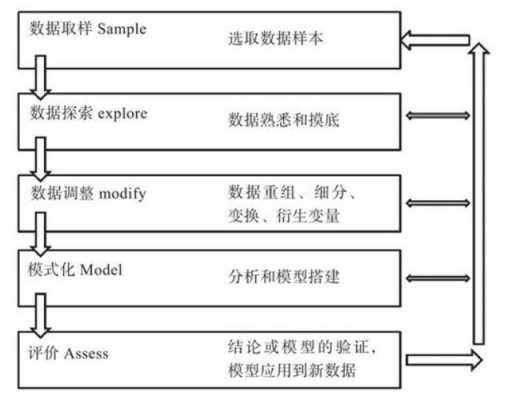
数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。数据挖掘流程:定义问题:清晰地定义出业务问题,确定数据挖掘的目的。
-图3")
数据挖掘是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
数据挖掘一般是指从大量的数据中自动搜索隐藏于其中的有着特殊关系性(属于Association rule learning)的信息的过程。
到此,以上就是小编对于文本挖掘数据集的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏