本篇目录:
- 1、应用Spark技术,SoData数据机器人实现快速、通用数据治理
- 2、etl清洗数据与spark数据清洗区别
- 3、Spark踩坑vlog——join时shuffle的大坑
- 4、如何在可视化中加入spark技术
- 5、大数据技术常用的数据处理方式有哪些?
- 6、spark和hadoop的区别
应用Spark技术,SoData数据机器人实现快速、通用数据治理
1、也有许多数据治理工具,为了实现实时、通用的数据治理而采用Spark技术。以飞算推出的SoData数据机器人为例,是一套实时+批次、批流一体、高效的数据开发治理工具,能够帮助企业快速实现数据应用。
2、Apache Spark:Spark是一个快速、通用的大数据处理框架,它提供了丰富的API和工具,可以用于处理Excel数据。使用Spark SQL模块,你可以将Excel文件加载到DataFrame中,并进行各种数据转换和分析操作。
-图1")
3、其实医院信息科真正需要的不应该是Hadoop、Spark、Flink等大数据技术的堆砌,应该是信息科都可以简单上手操作做数据治理,以这些技术为基础的能解决业务问题的产品。
etl清洗数据与spark数据清洗区别
1、Spark基于内存计算的准Mapreduce,在离线数据处理中,一般使用Spark sql进行数据清洗,目标文件一般是放在hdf或者nfs上,在书写sql的时候,尽量少用distinct,group by reducebykey 等之类的算子,要防止数据倾斜。
2、数据清洗:MapReduce作为Hadoop的查询引擎,用于大规模数据集的并行计算。数据查询分析:Hive的核心工作就是把SQL语句翻译成MR程序,可以将结构化的数据映射为一张数据库表,并提供HQL(HiveSQL)查询功能。
3、数据收集:从数据源中获取数据,可能是通过传感器、网络、文件导入等方式。数据清洗:对数据进行初步处理,包括去重、缺失值填充、异常值处理等。
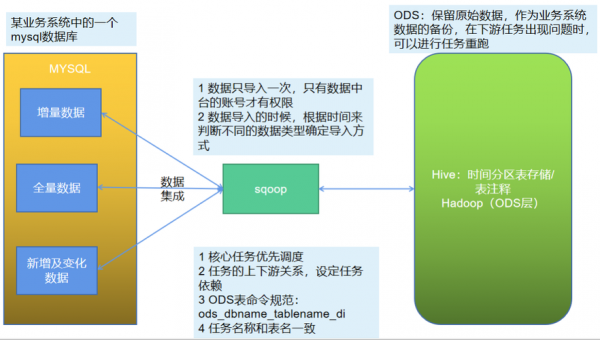
-图2")
Spark踩坑vlog——join时shuffle的大坑
Spark的join操作可能触发shuffle操作。shuffle操作要经过磁盘IO,网络传输,对性能影响比较大。本文聊一聊Spark的join在哪些情况下可以避免shuffle过程。
如何在可视化中加入spark技术
1、通过将Spark与可视化工具结合使用,可以交互地处理和可视化复杂的数据集。下一版本的Apache Spark(Spark 0)将于今年的4月或5月首次亮相,它将具有一项新功能- 结构化流 -使用户能够对实时数据执行交互式查询。
2、创建画布 在 可视化建模 选项卡中单击 新建 ,就可创建一个模型画布。同时,会在系统界面右侧自动停靠工具箱面板。 添加模型 工具箱中的各种模型工具,是整个工作流程构成的基本单元。
3、除了具备Spark数据处理的优势,SoData数据机器人的Spark体系还支持从各种数据源执行SQL生成Spark字典表,边开发边调试的Spark-SQL开发,支持任意结果集输出到各类数据库。
-图3")
4、方法一 /usr/local/Spark/bin/pyspark默认打开的是Python,而不是ipython。通过在pyspark文件中添加一行,来使用ipython打开。
5、最后的PhysicalPlan execution阶段用Spark代替Hadoop MapReduce。通过配置Shark参数,Shark可以自动在内存中缓存特定的RDD,实现数据重用,进而加快特定数据集的检索。
6、maven工程中添加jar有两种方式添。 第一: 通过【Dependencies】,可视化界面操作点击Dependencies标签页。点击【add】按钮 输入我们想添加的jar包名字进行搜索.就会出现下图中所示。
大数据技术常用的数据处理方式有哪些?
离线处理 离线处理方式已经相当成熟,它适用于量庞大且较长时间保存的数据。在离线处理过程中,大量数据可以进行批量运算,使得我们的查询能够快速响应得到结果。
通常的处理方法有:忽略元组、人工填写缺失值、使用一个全局变量填充缺失值、使用属性的中心度量填充缺失值、使用与给定元组属同一类的所有样本的属性均值或中位数、使用最可能的值填充缺失值。
可视化分析 不管是对数据分析专家还是普通用户,数据可视化是数据分析工具最基本的要求。可视化可以直观的展示数据,让数据自己说话,让观众听到结果。数据挖掘算法 可视化是给人看的,数据挖掘就是给机器看的。
数据变换 通过变换使用规范化、数据离散化和概念分层等方法,使得数据的挖掘可以在多个抽象层面上进行。数据变换操作是提升数据挖掘效果的附加预处理过程。
spark和hadoop的区别
spark和hadoop的区别就是原理以及数据的存储和处理等。Hadoop一个作业称为一个Job,Job里面分为Map Task和Reduce Task阶段,每个Task都在自己的进程中运行,当Task结束时,进程也会随之结束。
Spark 有很多行组件,功能更强大,速度更快。解决问题的层面不一样 首先,Hadoop和Apache Spark两者都是大数据框架,但是各自存在的目的不尽相同。
Hadoop分为两大部分:HDFS、Mapreduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。由于编写MapReduce程序繁琐复杂,而sql语言比较简单,程序员就开发出了支持sql的hive。
hadoop是分布式系统基础架构,是个大的框架,spark是这个大的架构下的一个内存计算框架,负责计算,同样作为计算框架的还有mapreduce,适用范围不同,比如hbase负责列式存储,hdfs文件系统等等。
到此,以上就是小编对于spark 过滤的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏