本篇目录:
大数据挖掘的算法有哪些?
有时也把数据挖掘分为:分类,回归,聚类,关联分析。
遗传算法 遗传算法是一种基于生物自然选择与遗传机理的随机搜索算法,是一种仿生全局优化方法。遗传算法具有的隐含并行性、易于和其它模型结合等性质使得它在数据挖掘中被加以应用。
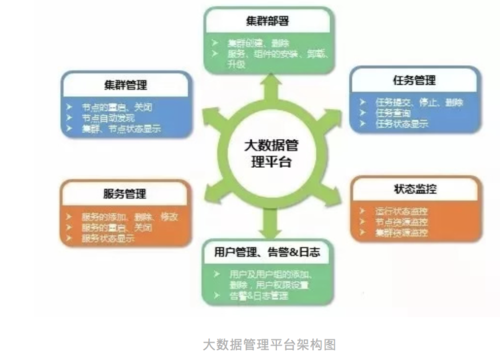
-图1")
常用的数据挖掘算法分为以下几类:神经网络,遗传算法,回归算法,聚类分析算法,贝耶斯算法。
需要分布式系统来处理。其中,数据挖掘经典十大算法为:C5,K-Means,SVM,Apriori,EM,PageRank,AdaBoost,KNN,NB和CART。常见的分布式计算有Hadoop spark等,如果要实时计算的,一般用Storm什么的。
方法(数据挖掘算法)如果说可视化用于人们观看,那么数据挖掘就是给机器看的。集群、分割、孤立点分析和其他算法使我们能够深入挖掘数据并挖掘价值。这些算法不仅要处理大量数据,还必须尽量缩减处理大数据的速度。
数据挖掘的的方法主要有以下几点: 分类挖掘方法。分类挖掘方法主要利用决策树进行分类,是一种高效且在数据挖掘方法中占有重要地位的挖掘方法。
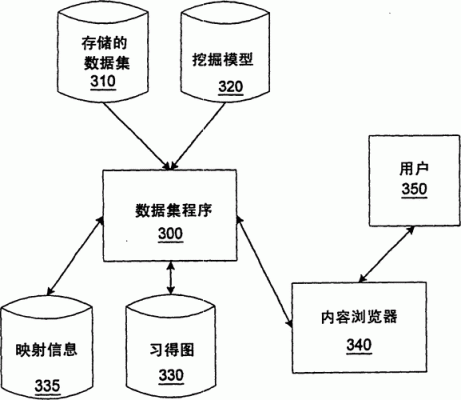
-图2")
数据挖掘十大经典算法之EM
1、EM:最大期望值法。pagerank:是google算法的重要内容。 Adaboost:是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器然后把弱分类器集合起来,构成一个更强的最终分类器。
2、Forgy方法易于使得初始均值点散开,随机划分方法则把均值点都放到靠近数据集中心的地方;随机划分方法一般更适用于k-调和均值和模糊k-均值算法。对于期望-最大化(EM)算法和标准k-means算法,Forgy方法作为初始化方法的表现会更好一些。
3、EM算法从任意一点 出发,依次利用E-step优化 ,M-step优化 ,重复上述过程从而逐渐逼近极大值点。而这个过程究竟是怎样的呢,就让我们一步步地揭开EM算法的面纱。
4、以下主要是常见的10种数据挖掘的算法,数据挖掘分为:分类(Logistic回归模型、神经网络、支持向量机等)、关联分析、聚类分析、孤立点分析。
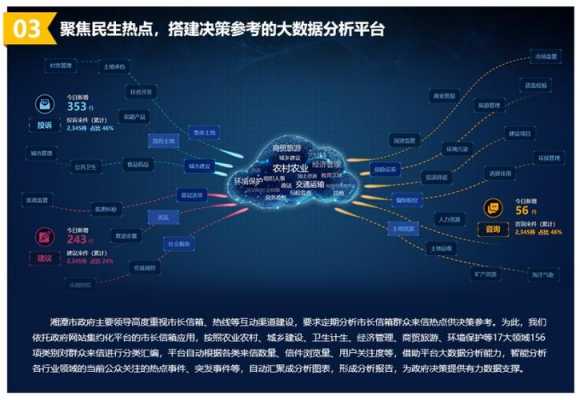
-图3")
大数据挖掘需要学习哪些技术大数据的工作
数据准备:开始收集数据,并对数据进行清洗、数据集成等操作,完成数据挖掘前的准备工作。模型建立:选择和应用各种数据挖掘模型,并进行优化,以便得到更好的分类结果。
大数据应用技术就业方向:互联网、物联网、人工智能、金融、体育、在线教育、交通、物流、电商等。
大数据方向需要学数据存储和分析技术、数据挖掘和机器学习技术、业务应用和商业分析等。数据存储和分析技术大数据的处理需要一个强大的平台,因此数据存储和分析技术是大数据方向中最基础和最重要的方面。
数据挖掘的工作内容是什么呢?数据分析更偏向统计分析,出图,作报告比较多,做一些展示。数据挖掘更偏向于建模型。比如,我们做一个电商的数据分析。万达电商的数据非常大,具体要做什么需要项目组自己来定。
大数据量的计算, 在单台服务器上是计算不了的, 这就需要用分布式计算, 所以要掌握各种分布式计算框架, 像hadoop, spark之类, 需要掌握机器学习算法的分布式实现。
大数据挖掘主要涉及以下四种: 关联规则关联规则使两个或多个项之间的关联以确定它们之间的模式。例如,超市可以确定顾客在买草莓时也常买鲜奶油,反之亦然。关联通常用于销售点系统,以确定产品之间的共同趋势。
到此,以上就是小编对于数据挖掘领域经典算法的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏