本篇目录:
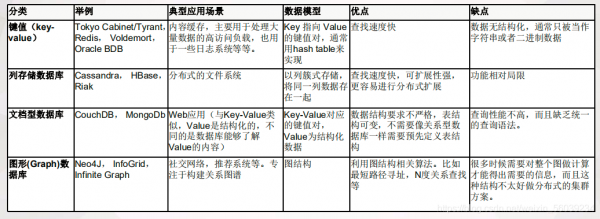
常见的大数据采集工具有哪些?
1、Scrapy是一款基于Python的高性能网络爬虫框架,它具有强大且灵活的数据提取能力,同时也支持多线程和异步操作的特性。Scrapy将爬取、数据提取和数据处理等流程集成在了一个框架中,能极大地提高爬虫的开发效率。
2、KNIME 开源数据分析平台。你可以迅速在其中部署、扩展和熟悉数据。 Python 一种免费的开源语言。关于有哪些好用的大数据采集平台,青藤小编就和您分享到这里了。
-图1")
3、第三,大数据可视化。在这个领域,最常用目前也是最优秀的软件莫过于TableAU了。TableAU的主要优势就是它支持多种的大数据源,还拥有较多的可视化图表类型,并且操作简单,容易上手,非常适合研究员使用。
4、数据搜集:借助工具对研究对象进行数据采集,可以是人工采集——如街头调查、电话采访、现场统计……,也可以是软件采集——如网络爬虫、GPS轨迹、企业ERP历史数据。
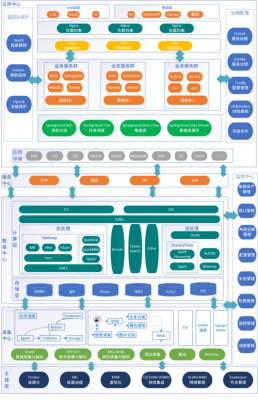
大数据Kafka有哪些优势能力呢?
kafka在消费端也有着高吞吐量,由于kafka是将数据写入到页缓存中,同时由于读写相间的间隔并不大,很大可能性会在缓存中命中,从而保证高吞吐量。
优势: 在性能方面kafka可以说是业界非常优秀的一款中间件,在常规的机器配置下,一台机器可以达到每秒几十万的QPS。
-图2")
Kafka的优点 1 解耦 在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。
Kafka 是一个分布式消息队列,具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
大数据Kafka是什么呢?
1、kafka的意思是:卡夫卡。Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
2、kafka在设计之初就是为了针对大数据量的传输处理,高吞吐量、低延迟最主要看的就是单位时间内所能读写的数据总量,我们先来看生产端。
-图3")
3、Kafka 本质其实也是消息中间件的一种,Kafka 出自于 LinkedIn 公司,与 2010 年开源到 github。
到此,以上就是小编对于大数据kafka接收文件数据的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏